A Prolog programozási nyelv
áttekintése
1. Bevezetés
2. Termek
4. Lekérdezések
9. Operátorok
10. Kiirás/Beolvasás
11. Vezérlőszerkezetek, vezérlésmódosítás
15. Kivételkezelés
16. Modularitás
17. OOP és öröklődés
18. A Prolog egy OO kiterjesztése: a Prolog++
22. Linkek
A Prolog (Programming in Logic) a deklaratív nyelvek, ezen belül a logikai programnyelvek családjába tartozik. A deklaratív nyelvek nem utasításokból, hanem függvénykapcsolatokból (funkcionális nyelvek) illetve relációkból (logikai nyelvek) épülnek fel; alapgondolatuk, hogy a programozó csak azt mondja meg, mit kell csinálni, a megoldás módját a program maga keresi meg. Jellegzetességük a matematikai változófogalom használata: egy változó a program futása során nem vehet fel különböző értékeket.
A Prolog lexikai elemei:
<változó> ::=
<nagybetű><alfanum>... | _<alfanum>...
<névkonstans> ::= '<névkar> ...' |
<kisbetű><alfanum>... |
<tapadójel>...
| ! | ; | [] | {}
<névkar> ::= {tetszőleges nem ' és nem \ karakter} | \<escape
szekvencia>
<alfanum> ::= <kisbetű> | <nagybetű> |
<számjegy> | _
<tapadó jel> ::= + | - | * | / | \ | $ | ^ | < | > | = | ' | ~ | :
| . | ? | @ | # | &
<egész szám> ::= {előjeles vagy előjeltelen számjegysorozat}
<lebegőpontos szám> ::= {belsejében tizedespontot tartalmazó
számjegysorozat esetleg exponenssel}
A változók mindig nagybetűvel vagy aláhúzással
kezdődnek, a konstansok vagy kisbetűvel kezdődnek vagy
aposztrófok között vannak vagy tapadójelek egymásutánjából állnak.
Néhány példa a megengedett kifejezésekre a Prologban:
- változónevek:
Fakt, FAKT, _fakt, X2, _2, sőt akár az _ is jó
- névkonstans:
fakt, =, 'fakt', 'István', [], **, \=, stb.
- számkonstans:
0, -123, 10.0, -12.1e8
Egy Prolog-program nem más
mint állítások (vagyis mondatok) sorozata. Egy ilyen mondat két részből
áll: egy fejből és egy törzsből. Ezek közül szintaktikailag nem
kötelező mindkettő használata (de legalább az egyiket kell), ekkor a
következő további elnevezések használatosak:
- ha
a mondatnak van feje és törzse is, akkor klóznak (ami igazából Horn-klóz)
nevezik, ami tulajdonképpen egy következtetési szabály abban az
értelemben, hogy a törzsben szereplő szabályok (részcélok)
teljesülése esetén a fejben szereplő állítás (céll) is teljesül,
- ha
a mondatnak hiányzik a törzse, akkor egységklóznak (vagy ténynek) nevezik,
- ha
a mondatnak a feje hiányzik, akkor a neve direktíva, a direktívák közül a
legfontosabb a lekérdezés lesz.
szintaxis:
<cél>.
<cél> :- <részcél>, ... ,<részcél>.
?- <részcél>, ... ,<részcél>.
Itt az első kifejezés az egységklóz, a
második a klóz (szabály), a harmadik pedig a
lekérdezés.
Kicsit más megvilágításba helyezve a dolgot,
egy Prolog-program tekinthető valamiféle egyszerű adatbázisnak is. Az
adatok egy része közvetlenül kerül tárolásra "tényállításként"
(egységklóz), a többi pedig kinyerhető a
következtetési szabályok (klózok) segítségével. Emiatt szokás a
Prolog-programokat Prolog-adatbázisként is emlegetni. Ezt az adatbázist a
programozó hozza létre, és a program végrehajtása közben kerül további
feldolgozásra az interpreter v. compiler által.
Egy Prolog-program végrehajtása a
lekérdezésben megfogalmazott állítás teljesülésének az eldöntését jelenti, amit
a programban található egyszerű állítások és a levezetési szabályok felhasználásával lehet elvégezni. Ezeket a
tényállításokat ill. levezetési szabályokat nevezzük célnak. Minden egyéb
procedurális jellegű művelet (pl. input és output) rekurzió
segítségével valósítható meg, vagy pedig egy bizonyos előredefiniált
(beépített) részcélra való hivatkozással (természetesen a levezetési szabály
törzsében). Az ilyen részcélok teljesítése a program többi részével szemben nem
lehet mellékhatásoktól mentes, gondoljunk csak a fájlkezelésre vagy a képernyőre való kiíratásra.
A Prolog program
felépítése:
<Prolog program>
::= <predikátum>...
<predikátum> ::= <klóz>...
<klóz> ::= <tényállítás>. |
<szabály>.
<tényállítás> ::= <fej>
<szabály> ::= <fej> :- <törzs>
<törzs> ::= <cél>...
<cél> ::= <kifejezés>
<fej> ::= <kifejezés>
Nézzük meg egy példán keresztül, hogyan is épül fel egy Prolog program!
Példa:
sum_tree(leaf(Value),Value).
sum_tree(node(Left,Right),S) :-
sum_tree(Left,S1), sum_tree(Right,S2), S is
S1 + S2.
A fenti Prolog kód egy predikátumot definiál, ez a sum_tree predikátum. Ez a predikátum egy relációt ír le egy
bináris fa és egy érték között, a fához a leveleinek összegét rendeli. A fenti
predikátumot két klózzal írtuk le.
Az első klóz egy tényállítás (csak fejből áll). Azt fejezi ki,
hogy egy egyetlen levélből álló fa levélösszege
maga a levél értéke. A tényállításokat feltétel nélkül igaznak tekintjük.
A második klóz egy szabály, ami <fej> :-
<törzs> alakú. Minden klózt egy ponttal, és egy szóközzel zártuk le a
nyelv szintaxisának megfelelően.
Ha egy predikátumot több klózzal írunk le, akkor a klózoknak azonos funktorúnak
kell lenniük. A funktor a predikátum nevét és argumentumainak számát mutatja. A
példában a klózok funktora sum_tree/2.
A Prolog kifejezés
A Prolog nyelv kifejezés-fogalma az alábbi szintaxis
szerint épül fel. A jobb oldalon felsorolt angol szavak az adott kifejezésfajta
angol nevét, és egyben a kifejezésfajtát ellenőrző beépített eljárás
nevét adják meg.
<kifejezés> ::= <változó> |
{var}
<konstans> |
{atomic}
<összetett kifejezés>
{compound}
<konstans> ::= <névkonstans> | {atom}
<számkonstans>
{number}
<számkonstans> ::= <egész szám> |
{integer}
<lebegőpontos szám> {float}
<összetett kifejezés> ::= <struktúranév> (
<argumentum> ,
)
<struktúranév> ::= <névkonstans>
<argumentum> ::= <kifejezés>
Például a sum_tree(node(Left,Right),S) egy összetett kifejezés. Struktúraneve
sum_tree, argumentumlistája két argumentumot tartalmaz, az egyik a node(Left,Right), amely szintén egy összetett kifejezés, a
másik az S változó. De mi van a példában szereplő S is S1 + S2
kifejezéssel? Ez egy ún. operátoros kifejezés, melynek
belső kanonikus alakja: is(S , +( S1 , S2 )) . Tehát funktora is/2, és
második argumentuma szintén egy operátoros kifejezés a +/2 funktorral. Adott
kifejezésről eldönthető, hogy változó, egész szám vagy más
kifejezésfajta az osztályozó beépített eljárások segítségével. Ezek a következők:
- var(X) X
változó
- nonvar(X) X
nem változó
- atomic(X) X
konstans
- compound(X) X
struktúra
- atom(X)
X
atom
- number(X) X
szám
- integer(X) X
egész szám
- float(X)
X lebegőpontos szám
A Prolog nyelv elemi objektumai a termek. Ezek azok az objektumok, amelyekről bizonyos állításokat megfogalmazunk, és amelyekre a lekérdezésben megfogalmazott állítás vonatkozik. Termnek nevezzük tehát a konstansokat, a változókat és az összetett termeket.
A konstansok közé tartoznak a numerikus
konstansok (természetes illetve lebegőpontos), a sztringkonstansok,
továbbá az úgynevezett atomok. A természetes szám lehet decimális, bináris,
oktális vagy hexadecimális, utóbbiakat rendre a számjegyek előtti 0b, 0o
illetve 0x jelöli; vagy pedig karakterkonstans, 0'c alakban (ahol c egy
karakter vagy egy escape szekvencia a C nyelvbelivel azonos formában). A lebegőpontos
szám kötelezően tartalmazza a tizedespontot, annak mindkét oldalán
legalább egy számjegyet, és opcionálisan az exponenst. Az atomok azok az
absztrakt objektumok, amelyeknek nincs tovább bontható belső struktúrájuk
(nyilván innen az elnevezés is). Az atomok azok a termek, amelyek segítségével
modellezni tudjuk egy konkrét probléma "résztvevő" elemeit.
Szerepüket tekintve leginkább a természetes nyelvekben megtalálható főnevekhez
hasonlíthatóak. Az atomok elnevezésére tetszőleges kisbetűvel
kezdődő alfanumerikus sorozatot használhatunk.
A változók itt logikai változó értelemben
szerepelnek. Szemben a hagyományos programozási nyelvekkel most a változó nem
egy írható/olvasható memóriahelyet jelöl, hanem egy adat-objektum "lokális
nevét". A változók neve tetszőleges alfanumerikus karaktersorozat
lehet (beleértve az _ karaktert is), melyek vagy nagybetűvel,
vagy az _ karakterrel kezdődnek. Ha egy változóra csak egyszer hivatkozunk
egy klózon belül, akkor ezt nem kell megnevezni, és névtelen (anonymous)
változó gyanánt írjuk le, melyet az aláhúzás (_) karakter jelöl. Egy klóz
számos névtelen változót tartalmazhat, melyeket egyedi változók gyanánt kezel a
nyelv.
A Prolog lehetőséget biztosít az
atomoknál bonyolultabb felépítésű objektumok létrehozására is, amelyeket
struktúráknak neveznek. Egy ilyen struktúra szintaktikai szempontból egy
összetett termet jelent. Az összetett term egy funktorból és további termek
sorozatából áll, amelyeket a term argumentumainak hívnak.
példák:
-12.345
% numerikus konstans
"Gesztenye Guszti" % ez így egy
sztringkonstans
gesztenye_guszti % így egy atom
GG
% ez meg már változó
szemelyi_adatok("Szigor Igor", 30, ferfi)
% ez egy összetett term, ami
% felfogható egy rekordnak is
Ez utóbbihoz hasonló struktúra megtalálható
szinte minden programozási nyelvben, de a Prolog-beli összetett termeknek van
egy extra tulajdonságuk is. Nevezetesen ha a term egyes argumentumai logikai
változók, akkor az nem egy hanem több (valamilyen
szempontból azonos tulajdonságú) objektumot jelöl.
A termek közé tartozik tehát az összes
aritmetikai kifejezés is. Ilyen aritmetikai kifejezések létrehozhatóak az előre
beépített műveletek (funktorok) segítségével, vagyis a + - * / stb.
felhasználásával. Ezeket a funktorokat használhatjuk mind prefix mind pedig infix módon is.
Egy egyszerű állítás felfogható, mint valamiféle reláció az objektumok között. Ezt a relációt a predikátuma és az argumentumszáma azonosítja, ennek megfelelően ugyanazon predikátum segítségével több állítást is megfogalmazhatunk, méghozzá több különböző reláció esetében is. Ezeket az állításokat természetesen igaznak tekintjük, ezért akár axiómáknak is hívhatnánk őket. Logikai szempontból pedig ezek az egységklózok.
példa:
nem_oszthato( 5, 0 ).
egyenlo( 2 * 2, 5 ).
paros_szam(12).
A harmadik példára tekintve elmondhatjuk,
hogy ha egy objektum valamely tulajdonságát szeretnénk kifejezni, akkor erre
legalkalmasabb az egyargumentumú reláció. Természetesen nem csak a felhasználó
definiálhat ilyen predikátumot, hanem minden Prolog-implementáció tartalmaz előre
definiált predikátumokat is.
A predikátumokat nevükkel és aritásukkal jellemezhetjük, név/aritás formájában.
Az aritás egy predikátum argumentumainak száma. Egy relációt több állítás is
meghatározhat, ilyenkor beszélünk unióról.
Például a szülője/2 reláció az anyja/2
és az apja/2 relációk uniója:
szülője(X,Y) :- anyja(X,Y).
szülője(X,Y) :- apja(X,Y).
Ahhoz, hogy a Prolog-interpreter (v. compiler) eldönthesse bizonyos állítás (cél) igazságértékét, deklarálni kell egy lekérdezést a programszövegben, amely részcéljai között szerepel a kérdéses állítás. Egyáltalán ha azt akarjuk, hogy a programunk valahol elkezdje a futását, akkor szükséges egy lekérdezés deklarálása is. Például (az előbbi példát folytatva):
?- egyenlo(5,5).
lekérdezésre a rendszer egy "No"-val fog válaszolni,
ugyanis a lekérdezésben megfogalmazott állítást egyik korábban deklarált
állításra sem tudta illeszteni. Továbbá a:
?- nem_oszthato(5,X), write(X).
kérdésre a válasz "Yes" lesz, ugyanis a 0 konstanst
az X változóval helyettesítve (amit meg lehet tenni) illeszteni tudjuk a
keresett részcélt. Ez tulajdonképpen azt jelenti, hogy a Prolog-fordító el
tudja dönteni, hogy létezik-e olyan X melyre teljesül a fenti állítás, és ez az
objektum a 0. Mindezeknek az lesz a hatása, hogy az X változó a 0 konstanssal
példányosul, és az adott mondat (itt maga a lekérdezés) törzsének hátralevő
részében az X változóhivatkozás a 0 konstanst fogja jelenteni. Tehát a
"write" beépített predikátum illesztésének a hatására a képernyőre
a 0 szám fog kerülni.
A gyakorlatban sokszor van szükség több hasonló fajtájú állítás megfogalmazásra (paraméteres állítás). Például:
nem_oszthato( X, 0 ). % egyik szám sem
osztható 0-val
Ekkor a következő lekérdezésre
természetesen "Yes" a válasz:
?- nem_oszthato( 231234, 0 ).
Sőt az első argumentumba bármit is
írva (és nem csak egész konstanst!) a válasz pozitív lesz. Az ilyen paraméteres
állítások segítségével tudunk továbbá univerzálisan kvantált formulákat
Prolog-ban interpretálni.
Nyilván egy Prolog-programnak nem kell tartalmaznia az összes olyan állítást, melyek pozitív megválaszolására képes. Sok állítás igazságértéke kikövetkeztethető a többi állítás felhasználásával (rezolúció). Például ne kelljen megadnunk egy rendezési relációt objektumok bizonyos halmazán úgy, hogy az összes lehetséges párosítást felsoroljuk. Helyette nagyon sok állítást kiválthatunk, ha deklaráljuk a tranzitivitási tulajdonságot axiómaként. Tehát:
r(a,b).
r(b,c).
r(c,d).
r(d,e).
r(X,Y) :- r(X,Z), r(Z,Y).
És itt az utolsó deklaráció már egy
levezetési szabály (mondat).
A mondat törzsében található célokat alapvetően
a "," karakter határolja el, mely a logikai és-nek felel meg. Sokszor
szükségünk lehet ennek párjára (a logikai vagy-ra). Ezt úgy oldhatjuk
meg ha azonos fejjel szétbontjuk mondatunkat további mondatokra,
mely szemantikailag - az illesztés szabályai miatt szintén a logikai
vagy-nak fog megfelelni. A mondatokat - akár a természetes nyelvekben a
pont (".") karakter terminálja.
Egy Prolog programra kétféle szemantika
adható: tekinthetjük logikai formulák halmazaként (deklaratív értelmezés), vagy
algoritmusként (procedurális értelmezés). Bár a deklaratív értelmezés alapján
megállapítható a program helyessége, csak a procedurális értelmezésből
dönthető el, hogy nem kerül-e végtelen ciklusba, és a nyelv nem-deklaratív
elemei is megnehezítik a logikai értelmezést.
A procedurális szemlélet szerint a Prolog programban szereplő, azonos nevű
és argumentumszámú klózok egy eljárást alkotnak. Az
eljárást meghatározó név/argumentumszám párost az eljárás funktorának nevezzük.
Ha az eljárás több klózból áll, ezeket eljárásváltozatoknak nevezzük. Minden
lekérdezés megfelel egy eljáráshívásnak. A paraméterátadás egy kétirányú
mintaillesztés segítségével történik, amit egyesítésnek hívunk. Abban a
sorrendben próbáljuk az eljáráshívást az eljárásváltozatokkal egyesíteni,
amelyben azokat a programban definiáltuk; egy ilyen egyesítési kísérlet neve
redukciós lépés. A redukciós lépés sikeres, ha a hívás és a klóz feje
változó-behelyettesítéssel azonos alakra hozható, ekkor a célsorozatban (a
célvezérelt keresésből átvett fogalom; a célsorozatban tartjuk nyilván a
még meg nem vizsgált feltételeket, kezdetben megegyezik a lekérdezéssel) a
változó-behelyettesítések után az első elemet az illesztett klóz törzsére cseréljük le (ha a klóz tényállítás volt, az első
elemet töröljük). A végrehajtási mechanizmus a visszalépéses keresésen
alapszik, az algoritmus pszeudokódja (CS a pillanatnyi célsorozat, I az
aktuális klóz sorszáma az eljáráson belül):
- (Kezdeti
beállítások:) A verem kezdetben legyen üres, CS
:= kezdeti célsorozat
- (Beépített
eljárások:) Tekintsük a CS célsorozat első hívását. Ha ez beépített
eljárásra vonatkozik, akkor hajtsuk végre az eljárást:
- Ha
a végrehajtás sikertelen, akkor menjünk a 6. lépésre.
- Ha
a végrehajtás sikeres, akkor végezzük el a beépített eljárás által
esetleg kiváltott behelyettesítéseket a CS sorozaton, hagyjuk el az első
hívást, és az így kapott célsorozatot tekintsük a továbbiakban CS-nek.
Ezután folytassuk a 5. lépéssel.
- (Klózszámláló
kezdőértékezése:) Legyen I = 1.
- (Redukciós
lépés:) Itt CS első hívása nem beépített. Tekintsük a híváshoz
tartozó eljárásdefiníciót, legyen az ebben levő
klózok száma N.
- Ha
I > N, akkor menjünk a 6. lépésre.
- Tekintsük
a definíció I-edik klózát és kíséreljünk meg egy redukciós lépést erre a
klózra és a CS célsorozatra.
- Ha
a redukciós lépés sikertelen, akkor I := I+1, és
(változatlan CS mellett) ismételjük a 4. lépést.
- Itt
a redukciós lépés sikeres. Ha I < N (nem
utolsó klóz), akkor mentsük el a verem tetejére a <CS, I> párt.
- A
redukciós lépés eredményeként kapott célsorozatot tekintjük CS-nek.
- (Siker:)
Ha CS üres sorozat, akkor a végrehajtási algoritmus sikeresen véget ért,
egyébként folytassuk a 2. lépésnél.
- (Sikertelenség:)
Ha a verem üres, akkor a végrehajtás sikertelenül véget ért.
- (Visszalépés:)
Ha a verem nem üres, akkor leemeljük a verem tetején levő <CS,
I> párt, ebből visszaállítjuk a CS és I változók értékét. Ezután I := I+1, és folytatjuk a 4. lépésnél.
Siker esetén az alkalmazott helyettesítésekből
nyerjük a megoldást; ha az esetleges további megoldásokra is kíváncsiak
vagyunk, a végrehajtást folytatnunk kell a 7. ponttal.
Keresési
fa
Egy prolog program végrehajtása
tekinthető keresési fájának visszalépéses bejárásának is. A keresési fa
gyökere az eredeti cél, csúcsai a levezetés során előállított
célsorozatok, élei a célredukciós lépések és levelei az üres célsorozatok, a
megoldáslevelek, vagy ahol a részcél nem redukálható, a fail-levelek. Minden
megoldáslevélhez az eredeti kérdés egy-egy megoldása tartozik. A prolog
végrehajtási mechanizmusa – mint a fentebbi leírásból is kiolvasható – legbal
részcélkiválasztási módszer, vagyis mindig az első részcélt választjuk ki,
és ezt próbáljuk helyettesíteni vagy egyesíteni. Tehát a Prolog gép
visszalépéses kereséssel bejárja a keresési fát, ennek ágait természetesen nem
építi fel előre, és visszalépéskor le is bontja, ezzel optimalizálva a
futó program memóriaigényét.
Az egyesítési algoritmus szolgál annak
eldöntésére, hogy két kifejezéssorozat milyen változó-behelyettesítések mellett
felel meg egymásnak.
Legyenek A1 ... AN és B1 ...
BN az egyesítendő sorozatok:
- Ha
N>1, akkor megkíséreljük az A1 és B1 egyelemű
sorozatok egyesítését. Ezután elvégezzük a kapott behelyettesítést az A2 , . . . , AN , ill. B2 , . . . , BN sorozatokon,
majd megkíséreljük ezeket a sorozatokat is egyesíteni. Az eredő
egyesítés akkor és csak akkor sikeres, ha mindkét rész-egyesítés sikeres. A
eredményezett behelyettesítést úgy kapjuk meg, hogy a kapott két behelyettesítés eredőjét vesszük. A továbbiakban feltételezhetjük, hogy N=1. - Ha
A1 és B1 azonos változók vagy konstansok, akkor az egyesítés sikeres, üres
behelyettesítéssel.
- Egyébként,
ha A1 változó, akkor az egyesítés sikeres az A1 = B1 behelyettesítéssel.
- Egyébként,
ha B 1 változó, akkor az egyesítés sikeres a B1 = A1 behelyettesítéssel.
- Ha
A1 és B1 azonos nevű és argumentumszámú összetett kifejezések, akkor
rekurzívan meghívjuk az egyesítési algoritmust A1 és B1 argumentumainak
sorozatára. Egyesítésük akkor és csak akkor sikeres, ha az
argumentum-sorozatok egyesítése sikerül.
- Minden
más esetben az egyesítés meghiúsul.
Megjegyzés: az egyesítés fogalmának
tételbizonyításbeli definíciója szerint, valahányszor egy X = Y
behelyettesítést hajtunk végre, ellenőrizni kell, hogy az X változó előfordul-e
az Y kifejezés belsejében. Ez az ún. előfordulás-ellenőrzés
(occurs check)). Ha az előfordulás-ellenőrzés sikeres, akkor, az
egyesítésnek elvben meg kell hiúsulnia. Hatékonysági okokból a legtöbb Prolog
elhagyja ezt a vizsgálatot,
Az operátorok a prologban a szintetikus
édesítőszerek közé tartoznak: olyan egy- vagy kétargumentumú struktúrák,
amelyek infix jelöléssel is írhatóak.Az operátorokat a
rendszer mindig szabványos alakra transzformálja, és csak utána végzi el az
illesztést. (Így például a+b+c egyesíthető X+c -vel, de nem egyesíthető
a+X-szel, mert szabványos alakja +(+(a, b), c.)
A programozó maga is definiálhat új operátort, ennek
formája:
:- op(prioritás, fajta, operátornév).
Az operátornév tetszőleges névkonstans lehet. A
prioritás egy 1 és 1200 közötti szám, a fajta pedig az
azonos prioritású operátorok közötti zárójelezés sorrendjét jelölő
sztringkonstans: yfx jelzi a balról jobbra kötő operátort, xfy a balról
jobbra kötőt, az xfx operátor egyik oldalán sem használható azonos
prioritású operátor zárójelezés nélkül. Hasonlóan, az egyoperandusú operátorok
yf, fy, xf vagy fx típusúak lehetnek.
A Prolog beépített szabványos operátorainak listája:
1200 xfx :-, -->
1200 fx :-, ?-1100 xfy ;1050 xfy ->1000 xfy ','900 fy \+700 xfx <, =, /=, =.., =:=, =<, ==, =\=. >, >=, @<, @=<, @>, @>=, \==, is500 yfx +, -, /\, \/400 yfx *, /, //, rem, mod, <<, >>200 xfx **200 xfx ^200 fy -, \
Mivel a mondatokban használatos összekötő jelek
is szabványos operátorok, így a mondat egyetlen kifejezésként is felírható, ami
lehetőséget ad a meta-programozásra: pl. dinamikus predikátumokat
hozhatunk létre, amiket futási időben módosítunk.
A levélösszeg számító példákban láttunk egy S is S1+S2
célt a második klózban. Már korábban is utaltunk arra, hogy ez egy operátoros
kifejezés. Itt az is és a + névkonstansok ún. operátorok,
melyek hívások ill. adatstruktúrák infix jelöléssel való írását teszik lehetővé.
Az operátorok "szintaktikus édesítőszerek", mert a kifejezés
beolvasását követően eltűnnek, a rendszeren belül a kifejezés
szabványos alakú lesz. A fenti példa esetén ez a
is(S,+(S1,S2)) alak, tehát az is/2 eljárás meghívásáról van szó, amelynek
második argumentuma a + nevű két argumentumú rekord struktúra.
Hasonlóképpen a S1+S2>1000 hívás szabványos alakja:
>(+(S1,S2),1000).
Az operátorok felhasználása
A Prolog általános operátorfogalma többféle módon is
megkönnyíti a programfejlesztési munkát. Először is az operátorfogalom
teszi lehetővé, hogy az aritmetikai beépített eljárásokban a megszokotthoz
hasonló módon írjuk le a számításainkat, pl.
X
is N*8 + A mod 8
Másodszor, az operátorfogalom teszi azt is lehetővé, hogy a Prolog
szabályokat, vezérlési szerkezeteket le tudjuk írni
mint Prolog-kifejezéseket. Ez a homogén szintaxis nemcsak a rendszer
megvalósítóinak könnyíti, de számos ún. meta-programozási lehetőségre ad
módot. Például lehetőség van ún. dinamikus predikátumok létrehozására,
amelyekhez futási időben adhatunk hozzá új klózokat, pl.
...,asserta((p(X):-q(X),r(X))),...
Harmadszor, operátorok segítségével a Prolog programok természetesebbé,
olvashatóbbá tehetők. (fontos értenünk, hogy ez csak számunkra olvashatóbb
alak, a Prolog rendszer úgyis szabványos alakra hoz mindent).
Negyedszer, operátorokat használhatunkaz adatok természetesebb formában való
leírására is. Például, ha a '.' jelet operátornak deklaráljuk, akkor kémiai
vegyületek leírására a szakmai nyelvhez közel álló jelölést használhatunk:
:-op(100,xfx,[.]).
sav(kén,h.2-s-o.4).
Végezetül az operátorok teszik lehetővé a "klasszikus"
szimbolikus kifejezésfeldolgozást, például a szimbolikus deriválást.
Rossz tulajdonságai is vannak az operátoroknak. Az operátorok nem lokálisak az
adott Prolog modulra nézve, ezért egy nagyobb projektben gondot jelenthetnek
más emberek által megírt vagy átdefiniált operátorok számunkra (például tudtunk
nélkül egyik napról a másikra egy általunk használt operátor prioritását valaki
más megváltoztathatja).
Bináris fa - operátoros változat
Ebben a szakaszban bemutatjuk az operátorok alkalmazását a
jól ismert binárisfa-példánk egyszerűbb, nem-megkülönböztetett uniót használó
változatában. Definiálunk egy - - nevű xfx típusú operátort:
:-op(500,xfx,--).
Ez a "--" név fogja helyettesíteni az eddigi node struktúranevet.
Mivel azonban a "--" operátort ínfixnek deklaráltuk, sokkal
kényelmesebben írhatunk le egy fát:
5--(3--2)
Ez megfelel a
--(5,--(3,2))
szabványos alaknak, amikoris ha -- helyére node-ot írunk, visszajutunk a
régebbi alakra. Az operátorral tehát csak annyit nyertünk,
hogy könnyebben olvashatóbbá tettük a fánk leírását, valamint a kódunkat is:
sum_tree3(Left--Right,S):-
sum_tree3(Left,S1),
sum_tree3(Right,S2),
S is S1 + S2.
sum_tree3(Tree,S):-
integer(Tree),
S = Tree.
A kifejezések írása és olvasásakor fontos szerepet játszanak az operátorok.
Fontos, hogy ügyeljünk arra, hogy a kiíráskor élő operátorok beolvasáskor
is éljenek, különben a beolvasás nem (vagy nem megfelelően) sikerül.
Operátorok deklarálása
op/3
Hivási minta:
op(+Prec,+Tipus,+Név)
Argumentumok:
Prec : Az
argumentum egy 0-1200 közötti egész
Tipus : Az
argumentum az fx, fy, xfx, xfy, yfx nevek valamelyike
Név : Az
argumentum egy név
Hatás:
Ha Prec > 0, akkor Név-et felveszi az operátortáblába Prec
precedenciával és Tipus típussal. Ha Prec = 0, akkor eltávolítja Név-et
az operátortáblából.
current_op/3
Hivási minta:
current_op(?Prec,?Tipus,?Név)
Argumentumok:
Prec : Az
argumentum egy 0-1200 közötti egész
Tipus : Az
argumentum az fx, fy, xfx, xfy, yfx nevek valamelyike
Név : Az
argumentum egy név
Jelentés:
Igaz, ha a Név operátor Prec precedenciával és Tipus típussal
szerepel az operátortáblában. Többszörösen sikerülhet.
Kifejezések kiírása
write/1, write_term/2
Hivási minta:
write(@X)
write_term(@X,@Opciók)
Argumentumok:
X : Az
argumentum egy tetszőleges kifejezés
Opciók : Az
argumentum írási opciók listája
Hatás:
Kiírja X-et az Opciók listának megfelelően. A write/1 ha szükséges operátorokat, zárójeleket használ.
Megjegyzések:
A write(X) hivás hatása megegyezik a
write(X,[]) híváséval.
Az irási opciók:
quoted(B) : Ha B true,
akkor minden nevet egyszeres idézőjelek között ir ki amennyiben ez szükséges
ahhoz, hogy a read/1 eljárás be tudja olvasni.
ignore_ops(B) : Ha B true, akkor az összetett kifejezéseket
funkcionális jelöléssel írja ki, sem operátorokat, sem listajelölést nem
használ.
numbervars(B)
: Ha B true, akkor a '$VAR'(N) alakú kifejezéseket (ahol N egy egész
szám) egy nagybetű és számok sorozataként írja ki. A
nagybetű az angol ABC (N mod 26)+1 sorszámú betűje lesz, a követő
szám pedig N//26 lesz, feltéve, hogy ez nem 0.
writeq/1
Hívási minta:
writeq(@X)
Argumentumok:
X : Az
argumentum egy tetszőleges kifejezés
Hatás:
Mint write(X), csak gondoskodik, hogy szükség esetén a nevek
idézőjelek közé legyenek téve, hogy a kiirt kifejezés read-del
visszaolvasható legyen (feltéve, hogy olvasáskor a használt operátorok deklarálva
vannak).
write_canonical/1
Hívási minta:
write_canonical(@X)
Argumentumok:
X : Az
argumentum egy tetszőleges kifejezés
Hatás:
Mint writeq(X), csak operátorok nélkül, minden struktúra
szabványos alakban jelenik meg.
Példa:
| ?- write_canonical(1+2).
+(1,2)
yes
write_canonical([1,2]-[]).
-(.(1,.(2,[])),[])
yes
print/1
Hívási minta:
print(@X)
Argumentumok:
X : Az
argumentum egy tetszőleges kifejezés
Hatás:
Alapértelmezésben azonos write-tal. Ha a
felhasználó definiál egy portray/1 eljárást, akkor a rendszer minden a
print-tel kinyomtatandó részkifejezésre meghívja a portray-t. Ha ez a hívás
sikerül, akkor feltételezi, hogy a portray elvégezte a szükséges kiírást, ha
meghiúsul, akkor maga írja ki a részkifejezést.
portray/1
Hivási minta:
portray(@Kif)
Jelentés:
Igaz, ha Kif kifejezést a Prolog rendszernek nem kell kiírnia.
Hatás:
Alkalmas formában kiírja a Kif kifejezést.
Megjegyzések:
Ez egy felhasználó által definiálandó (kampó)
eljárás (hook predicate).
Például ha felvesszük a következő
klózt:
portray(szemely(Nev,_,_)):-write(szemely(Nev,...)).
akkor a print/1 a következőképp működik:
| ?-
print([szemely(kiss,istvan,1960),szemely(nagy,gabor,1945)]).
[szemely(kiss,...),szemely(nagy,...)]
Yes
Formázott kifejezés-kiírás
format/2
Hivási minta:
format(@Formátum,@AdatLista)
Argumentumok:
Formátum :
Az argumentum egy név vagy karakterkódok listája
AdatLista :
Az argumentum tetszőleges kifejezések listája
Hatás:
A Formátum-nak megfelelő módon kiírja AdatLista-t.
A formázójelek alakja: ~<szám><formázójel>
A format/2 legfontosabb formázójelei:
Adattal:
·
d - (decimális)
egész szám
·
D - (decimális)
szám, csoportosítva
·
f - lebegőpontos
szám
·
w - tetszőleges
kifejezés (mint write)
·
q - tetszőleges
kifejezés (mint writeq)
·
p - tetszőleges
kifejezés (mint print)
Adat nélkül:
·
t - tabuláció
·
n - újsor
·
| - abszolút
tabulátorpozició
·
+ - relatív
tabulátorpozició
Példa:
simple_statistics :-
<obtain statistics>
format('~tStatistics~t~72|~n~n'),
format('Runtime: ~'.t ~2f~34|
Interferences: ~'.t ~D~72|~n',[RunT,Inf]),
...
Eredménye:
Statistics
Runtime: ............. 3.45
Interferences: ........ 60.345
Kifejezések beolvasása
read/1, read_term/2
Hivási minta:
read(?Kif)
read_term(?Kif,+Opciók)
Argumentumok:
Kif : Az
argumentum egy tetszőleges kifejezés
Opciók :
Az argumentum olvasási opciók listája
Jelentés:
Igaz, ha a beolvasott kifejezés egyesíthető a Kif
kifejezéssel és az Opciók listában szereplő opciók egyesíthetők a
kifejezéshez tartozó opciókkal.
Hatás:
Beolvas egy ponttal lezárt kifejezést, egyesíti
Kif-fel és kitölti a megadott opció-listát.
Megjegyzések:
File végénél Kif = end_of_file. A read(X) hivás megegyezik a read_term(X,[]) hívással.
Olvasási opciók:
variables(V)
: V a beolvasott kifejezésben szereplő
változók listája (balról jobbra haladva)
variable_names(VN)
: VN A=V alakú párok listája, ahol V a
beolvasott kifejezésben szereplő nem névtelen változó, A
pedig egy atom, amely nyomtatott alakja megegyezik a változó nevével.
singletons(Sz)
: Sz A=V alakú párok listája, ahol V egy
a beolvasott kifejezésben pontosan egyszer előforduló nem névtelen
változó, A pedig egy atom, amely nyomtatott alakja
megegyezik a változó nevével.
char_conversion/2
Hivási minta:
char_conversion(+KarBe,+KarKi)
Argumentumok:
KarBe
: Az argumentum egy karakter
KarKi
: Az argumentum egy karakter
Hatás:
A KarBe -> KarKi párt
hozzáveszi az aktuális karakterkonverziós leképezéshez. Ezután egy kifejezés
beolvasása során KarBe összes idézőjelek közé nem tett előfordulását
lecseréli a KarKi karakterre.
Ha a két argumentum megegyezik, akkor a korábbi KarBe karakterhez tartozó párt eltávolítja
a leképezésből.
current_char_conversion/2
Hívási minta:
current_char_conversion(?KarBe,?KarKi)
Argumentumok:
KarBe
: Az argumentum egy karakter
KarKi
: Az argumentum egy karakter
Jelentés:
Igaz, ha a KarBe -> KarKi pár szerepel az aktuális
karakterkonverziós leképezésben. Többszörösen sikerülhet.
11. Vezérlőszerkezetek, vezérlésmódosítás
10.1.
Vezérlőszerkezetek
A Prologban procedurális értelemben vett vezérlőszerkezetek
nem találhatók meg beépített módon. Természetesen adhatunk logikai
programozásbeli interpretációt mindegyikre:
- a
szekvencia elemi részmondatok (célok, részcélok) egymásutánját jelenti,
tehát egy levezetési szabály törzse tekinthető részmondatok
szekvenciájának is, amely szekvenciát a levezetési szabály feje azonosít,
- a
ciklus a rekurzív logikai függvények segítségével oldható meg, ahol fel
kell vennünk egy plusz változót (mint ciklusváltozót),
melynek ellenőrzéséről és inkrementálásáról illetve
dekrementálásáról is nekünk kell gondoskodnunk, valamint a terminálási
feltételt is nekünk kell ellenőriznünk,
- az
elágazás az illesztési szabályok kapcsán valósítható meg, nevezetesen az elágazás
feltétele kell legyen az első mondat
törzsében az első illesztendő részcél, így amennyiben ez nem
teljesül, akkor a rendszer az illesztést a következő mondattal
folytatja, ez a megoldás teljes mértékben analóg a hagyományos
elágazásfogalommal.
A hagyományos értelemben vett eljárásfogalom sem
ismert, itt igazából az egyes predikátumok illesztése jelenti egy-egy
"alprogram" hívását. Visszatérési érték fogalma sem ismert, a
predikátum egyes argumentumai lehetnek az alábbiak:
1. Bemenő (ekkor egy "nem változó"
term-mel kell példányosuljon)
2. Kimenő (ekkor egy logikai változóval kell
példányosuljon)
3. Be- Kimenő (ez az eset tetszés ill. értelmezés
szerinti)
10.2. Vezérlésmódosítás
A tiszta Prolog nyelvben nem tudunk megfogalmazni
tagadást, pedig sok esetben szükségünk lehet rá. Például, hogy két term nem
illeszthető (A/=B),
nem tudjuk megfogalmazni, csak azt, hogy illeszthető-e (A=B). Azaz
negatív információt nem tudunk kikövetkeztetni programunkből, legfeljebb
azt, hogy egy adott állítás következik-e belőle. Ha feltehető, hogy
egy állítás igaz, ha következik a programból, azaz, ha bizonyítható, akkor egy
állítás negáltja pedig akkor igaz, ha nem
bizonyítható. Ha ekkor rendelkezni tudnánk arról, hogy mi történjen egy
sikeres, ill. sikertelen célsorozat esetén, eszközt kaphatnánk a tagadás
megvalósítására.
Feltételes
célok
A feltételes célok az egyik
legfontosabb vezérlésmódosító eszközök. Formája:
( if -> then
; else
)
Az if, then, else tetszőleges Prolog
célsorozatok lehetnek. Ha az if
célsorozat sikeres, a then
célsorozat kerül végrehajtásra, és ennek megoldásai adják a megoldást, különben pedig az else. A feltételes célok egymásba
ágyazhatók:
( if1 -> then1
; (if2 -> then2
; else
)
)
A
következő speciális megoldások is megengedettek:
|
( if ->
then) |
( if ->
then ; fail ) |
( if ->
then ; true ) |
A fail ill. true beépített eljárások (fail/0, true/0), melyek hívása mindig
meghiúsul, ill. mindig sikeres. Az első két speciális megoldás
tulajdonképpen egyenértékű. (Mivel az elsőnek nincs else ága, ott megoldások sincsenek,
ugyanúgy, mintha fail lenne az
else ágban.)
Ezek után
a bevezetőben említett problémát (hogy két term nem illeszthető) már
könnyedén meg tudjuk oldani:
%A/=B A nem
illeszthető B-vel
A/=B :- ( A = B -> fail
; true
)
Tagadás
A feltételes célok felhasználásával a tagadás közös
sémáját fogalmazhatjuk meg:
not(P) :- ( P -> fail
;true
)
A tagadás
e formája meta-predikátumnak tekinthető a Prologban. A meta-predikátum
olyan predikátum, melynek formális paramétere a szabálytörzsben is
megjelenő metacél (itt: P). Ekkor P-t meta-argumentumnak nevezzük. Ha P
sikeres, esetleges választási pontjait a feltételes szerkezet levágja, majd az else ágon a true hajtódik végre és a hívás sikeres
lesz.
Például:
nőtlen_hallgató(X) :- hallgató(X), not(nős(X))
Figyelembe
kell vennünk, hogy a tagadás ilyen megfogalmazása azonban nem igazi logikai
tagadás. Ez könnyen belátható, ha végiggondoljuk, hogy not(P) pontosan akkor sikeres, ha a P cél
meghiúsul (és így P-nek egyetlen megoldása sem adódik). Általában igaz, hogy a
Prolog tagadás logikai értelemben vett helyességének elégséges feltétele, hogy
a negált cél a meghívás pillanatában ne tartalmazzon változót, és keresési fája
véges legyen.
12. Beépített adattípusok, típuskonstrukciós eszközök,
absztrakt adattípusok
A Prologban csak két (a hagyományos értelemben vett) elemi típus van, az egész (Integer) és a lebegőpontos (Float). Természetesen - mivel logikai nyelv - implicit módon a logikai típus (Boolean) is "definiált". Ismert továbbá a sztring-típus is. Újabb típusok készítésére az összetett termek (COMPOUND TERM) állnak rendelkezésünkre:
- Lista: Csakúgy mint más programozási nyelvekben a Prologban is
a listát bizonyos objektumok véges sorozatának ábrázolására használjuk.
példa:
[1,eric_cartman,["Hello world",23.45],[],X,]
Érdekesség, hogy a lista elemeinek nem kell azonos
típusúnak lenniük (ez persze az eddigiek alapján igazán nem meglepő). Tehát
listát szögletes zárójelek között deklarálhatunk, vesszővel elválasztva az
elemeit. Ezen felül még hivatkozhatunk egy listára a
következőképpen is:
[H|T]
[F,S|T]
Az első esetben a listára a fejével és a
"maradék rész"-ével hivatkoztunk, a második
esetben pedig kikötjük, hogy a listának legyen legalább két eleme. Az üres
listára is van egy jelölés, ami többek között egy atom is:
[]
Összhangban az eddigiekkel a listák is tulajdonképpen
termek, amelyek speciális szintaxissal bírnak. A [H|T] lista
azonos a .(H,T) struktúrával.
Valódi, ill.
részleges listák
Vannak valódi, ill. részleges listák. Egy valódi lista
lehet üres, vagy nem üres, a nem üres valódi listákat a ’.’/2 függvényszimbólum segítségével építjük fel, kiindulva
a [] üres listából. Egy [X|Xs]
term pontosan akkor valódi lista, ha Xs valódi lista.
Például az [1,2,3] listát a
következő alakban írhatjuk fel: .(1,.(2,.(3,[]))) Egy
term akkor részleges lista, ha szabad változó, vagy [X|Xs] alakú, ahol Xs részleges lista. Azaz egy term akkor részleges lista,
ha nem valódi lista, de megfelelő változóhelyettesítéssel azzá
tehető. Tegyük fel például, hogy Xs szabad változó.
Ekkor Xs és [1,2|Xs] részleges listák, viszont az [Xs] és [1,2,Xs] valódi listák.
Listakezelő
predikátumok
Az alábbiakban néhány, a logikai programozás
szempontjából alapvető fontosságú listakezelő predikátum lesz
bemutatva:
1.
member predikátum
Egy lista elemeit a lista első eleme, és a
„maradék rész”-ben lévő elemek alkotják:
%member(X,Xs) :- X eleme az Xs listának
member(X,[X|_Xs]).
member(X,[_X|Xs]) :-
member(X,Xs).
A predikátumhívás előfeltétele, hogy a második
paraméter valódi lista legyen, különben a keresési fa végtelen lesz. Valódi
listánál azonban a keresési fa végességét garantálja, hogy a rekurzióban a
lista hosszának csökkenése. Az itt alkalmazott programozási módszert rekurzív
keresésnek nevezzük.
2.
append predikátum
A listaösszefűzés programjánál is két állításunk
van. Az egyik arra az esetre vonatkozik, ha a lista üres, ez egy gyakori
módszer predikátumok megfogalmazásakor.
%append(Xs,Ys,Zs) :- az Xs és Ys
listák összefűzése a Zs lista
append([],Ys,Ys).
append([X|Xs],Ys,[X|Zs]) :-
append(Xs,Ys,Zs).
3.
rev_app
predikátum
Ezzel a predikátummal egy lista fordítottját és egy másik
listát fűzünk össze. Ha végiggondoljuk a rekurzió lépéseit, észrevehetjük,
hogy az első lista hossza csökken, a második argumentumban lévő lista
hossza pedig nő. Ezt az argumentumot nevezzük
akkumulátor-argumentumnak, mivel ebben építjük fel az adatszerkezetet alulról
fölfelé. A harmadik paraméter az alagút-paraméter, erre az eredmény
visszaadásához van szükségünk. (A harmadik paraméter a rekurzió végéig
változatlan, csak a végén egyesítjük az akkumulátor argumentummal.)
%rev_app(Xs,Ys,Zs) :- az Xs lista
fordítottjának és Ys listának az
%
összefűzése Zs
rev_app([],Ys,Ys).
rev_app([X,Xs],Ys,Zs) :-
rev_app(Xs,[X,Ys],Zs).
4.
reverse
predikátum
%reverse(Xs,Ys) :- Az Xs lista
fordítottja az Ys
reverse(Xs,Ys) :-
rev_app(Xs,[],Ys).
Ez a predikátum az általánosítás módszerére ad példát,
azaz a problémát egy általánosabb problémára visszavezetve oldjuk meg.
- Rekord: A
rekord-deklaráció formája rekordnév(tag1, tag2,
... tagN). Például egy bináris fát megadhatunk az alábbi formában:
bintree(1, bintree(2, bintree(3, ures, ures), bintree(4, uresm ures)), bintree(5, ures, ures)).
Általában azt mondják, a Prolog típustalan nyelv. Ennek ellenére az eljárások
csak bizonyos adathalmazokon képesek dolgozni, így implicit módon ugyan, de
megjelenik a típusfogalom. Ezt érdemes feltüntetni valamilyen formában. Ez
egyrészt elősegíti egy Prolog program működésének jobb megértését,
másrészt bizonyos Prolog kiterjesztések használnak típusokat, ezért érdemes
megismerkedni velük.
Típusleírásnak tömör Prolog kifejezések egy halmazának megadását értjük(egy Prolog kifejezést tömörnek nevezünk, ha nem
tartalmaz változót). A típusleírás, nevéhez hűen, egy típust definiál.
Alaptípusok leírására használhatjuk az integer, float, number, atom, atomic és
any konstansokat. Az első öt típusnév a megfelelő konstanshalmazt
jelöli, az any típusnév pedig az összes Prolog
kifejezés halmazát.
Az alaptípusokból kiindulva definiálhatunk összetett típusokat. Ehhez meg kell
adnunk egy struktúranevet, valamint minden argumentumáról meg kell mondanunk,
hogy milyen típusú. A struktúranevet és az argumentumok típusait
megadó kifejezést kapcsos zárójelbe téve kapunk egy összetett típust leíró
kifejezést.
Például a {személy(atom,atom,integer)} kifejezés egy
típust definiál. Nevezetesen minden olyan Prolog kifejezés, melynek funktora
személy/3, első két argumentuma atom és a harmadik egész szám, ilyen
típusú.
Ezt precízebben és általánosabban úgy írhatjuk le, hogy a
{ valami(T1, ..., Tn) }
halmazkifejezés ekvivalens a
{ valami(e1, ..., en) |
e1 eleme T1,
, en eleme Tn }, n >= 0
kifejezéssel, azaz a halmaz minden olyan valami nevű struktúrát tartalmaz,
amelynek argumentumai render T1 , T2 , stb. típusúak.
Egy típust képezhetünk halmazok uniójaként a \/ operator felhasználásával.
Például helyes típusdefiníció az alábbi:
{
személy(atom,atom,integer) } \/ { atom-atom } \/ atom
Azaz például az alma-alma Prolog kifejezés ilyen típusú, de a
személy('Nagy','Béla',24) is. Azért, hogy hivatkozni tudjunk a típusra el kell neveznünk azt. Ezt az alábbi módon tehetjük meg
(Prolog megjegyzésként):
% :- type
<típusnév> = = <típusleírás>
Lássunk is rögtön két példát! Vegyük észre, hogy a második típust rekurzív
módon írtuk fel, a típusleírás hivatkozik ugyanis a típusnévre:
% :- type t1 = = {
atom-atom } \/ atom.
% :-
type ember = = { ember-atom } \/ atom.
Az eddig látott példákban a típusleírásban mindig csak
az atom típusnév szerepelt a {} zárójelpáron kívül. Ez nem szükségszerű,
tetszőleges típusnév szerepelhet így, olyan is, amelyet mi definiáltunk.
Ennek megfelelően az alábbi két (végtelenül egyszerű) példa
mindegyike helyes.
% :-
type új_típus1 = = ember.
% :-
type új_típus2 = = { ember }.
A két típus nem egyenlő. Az új_típus1 típus pontosan ugyanazt a halmazt
jelöli, mint az ember típus, új_típus2 azonban az egyetlen ember névkonstanst
tartalmazó halmazt. (Esetünkben új_típus2 valódi részhalmaza új_típus1-nek.
Egy megkülönböztetett unió csupa különböző funktorú összetett típus
uniója. Fontos, hogy nem a struktúranévnek, hanem a funktornak kell
különböznie. Azaz nyugodtan lehet két azonos struktúranevű, de különböző
argumentumszámú típus. Megkülönböztetett uniót jelölhetünk a szokásos
:- type T = = { S1
} \/
\/ { Sn }
helyett így is:
:- type T ---> S1 ;
; Sn .
Fontos, hogy a megkülönböztetett unió is típus, csak éppen speciális. Két példa
megkülönböztetett unióra:
% :- type ember
---> ember-atom ; semmi.
% :-
type egészlista ---> [] ; [integer | egészlista]
Paraméteres típusok
Az előzőekben láttuk, hogy hogyan definiálhatunk saját típust.
Legutolsó példaként megadtunk egy olyan listát, amely egészeket tartalmaz. Jó
lenne, ha megadhatnánk egy lista-mintát is, azaz egy olyan típust, amely tetszőleges
(de egyforma) típusú elemek listája lehet.
Ugyanígy, bár tudunk definiálni olyan típust, amelyet az atom-atom alakú
struktúrák határoznak meg, szükségünk lehet egy olyan típusra, amelyet tetszőleges
típusú elemek párjai alkotnak. Erre szolgálnak az ún. Parameters típusok és
erre láthatunk példát az alábbiakban.
% :-
type list(T) ---> [] ; [ T | list(T)
].
(1)
% :- type pair( T1 , T2 )
---> T1 - T2.
(2)
% :- type assoc_list(
KeyT, ValueT ) = = list( pair(KeyT,ValueT). (3)
% :- type szótár = =
assoc_list( szó, szó
). (4)
% :- type szó = = atom.
(5)
(1) T típusú elemekből álló listákat foglal magába, (2) minden
olyan '-' nevű kétargumentumú struktúrát, amelynek első argumentuma
T1, második T2 típusú.
(3) egy olyan típust definiál, amelybe KeyT és ValueT típusú párokból álló
listák tartoznak. Végül (4) egy olyan, szótár nevű, típust határoz meg,
amelybe ( (5) alapján) atomokból képzett párokból álló
listák tartoznak. Ha belegondolunk, ez tényleg felfogható úgy, mint egy szótár.
A típusdeklarációk formális szintaxisa:
<típusdeklaráció> ::= <típuselnevezés> | <típuskonstrukció>
<típuselnevezés> ::= :- type <típusazonosító> = =
<típusleírás>
<típuskonstrukció> ::= :- type <típusazonosító> --->
<megkülönb. unió>
<megkülönb. unió> ::= <konstruktor> ;
<konstruktor> ::= <névkonstans> | <struktúranév>(
<típusleírás>,
)
<típusleírás> ::= <típusazonosító> | <típusváltozó> | {
<konstruktor> } |
<típusleírás>
\/ <típusleírás>
<típusazonosító> ::= <típusnév> | <típusnév>(
<típusváltozó>,
)
<típusnév> ::= <névkonstans>
<típusváltozó> ::= <változó>
Predikátumtípus-deklarációk
Egy predikátumtípus-deklaráció leírja, hogy egy predikátum milyen típusú
adatokat képes fogadni, illetve visszaadni az egyes argumentumaiban. Egy ilyen
deklaráció általánosan a következőképpen néz ki:
:- pred
<eljárásnév>( <típusleírás>,
)
Lássunk néhány példát az elmondottakra! Az első esetben a member/2
eljárásról jelentjük ki, hogy első argumentuma T típusú,
míg a második T típusú elmeket tartalmazó lista. Másodikként az append/3
eljárást írjuk le hasonló módon.
:- pred member( T, list(T) ).
:- pred append( list(T), list(T), list(T) ).
Nyilvánvaló, hogy egy predikátumtípus-deklarációban használhatóak ez előzetesen
megadott típusleírások.
Eljárásokkal kapcsolatban van még egy fontos fogalom, amit
predikátummód-deklarációnak hívunk. Egy ilyen deklaráció leírja, hogy az egyes
argumentumok kimenő vagy bemenő módban használatosak. Egy eljáráshoz
több ilyen móddeklaráció is megadható annak megfelelően, hogy az eljárás
milyen különböző módokban képes működni:
:- mode append(in,
in, in). % ellenőrzésre
:- mode append(in,
in, out). % két lista összefűzésére
:- mode append(out,
out, in). % egy lista szétszedésére
A predikátummód-deklaráció általános felépítése a
következő:
:- mode
<eljárásnév>( <módazonosító>,
)
ahol
<módazonosító> ::=
in | out.
Arra is van lehetőség, hogy egyetlen deklarációba fogjuk össze a típus- és
móddeklarációt is, például:
:- pred
between(integer::in, integer::in, integer::out).
Ilyen esetben az általános alak:
:- pred
<eljárásnév>( <típusazonosító>::<módazonosító>,
)
A SICStus kézikönyv a fentiektől eltérő
jelölést használ a bemenő/kimenő argumentumok jelzésére. Az append/3
esetén például:
append (+L1, ?L2,
-L3).
append (?L1, ?L2, +L3).
Az első jelöli az ellenőrzésre és két lista összefűzésére is
alkalmas megvalósítást, míg a második a szétszedésre is használhatót. Ennek
megfelelően a +, - és ? jelentése:
+ bemenő argumentum
- kimenő argumentum
? tetszőleges
argumentum
<mondat> ::= <kifejezés 1200> <záró-pont>
<kifejezés N> ::= <op N fx> <köz> <kifejezés N-1> | <op N fy> <köz> <kifejezés N> | <kifejezés N-1> <op N xfx> <kifejezés N-1> | <kifejezés N-1> <op N xfy> <kifejezés N> | <kifejezés N> <op N yfx> <kifejezés N-1> | <kifejezés N-1> <op N xf> | <kifejezés N> <op N yf> | <kifejezés N-1>
<kifejezés 1000> ::= <kifejezés 999> , <kifejezés 1000>
<kifejezés 0> ::= <név> ( <argumentumok> ) { A <név> és a nyitó zárójel közvetlenül egymás után kell álljon} | ( <kifejezés 1200> ) | { <kifejezés 1200> } | <lista> | <név> | <szám> | <füzér> | <változó>
<op N T> ::= <név> {feltéve, hogy <név> korábban N prioritású és T típusú operátornak lett deklarálva}
<argumentumok> ::= <kifejezés 999> | <kifejezés 999> , <argumentumok>
<lista> ::= [] | [ <listakif> ]
<listakif> ::= <kifejezés 999> | <kifejezés 999> , <listakif> | <kifejezés 999> | <kifejezés 999>
<szám> ::= <előjeltelen szám> | + <előjeltelen szám> | - <előjeltelen szám>
<előjeltelen szám> ::= <természetes szám> | < lebegőpontos szám>
Megjegyzések:
- Az
N-t tartalmazó szabályt minden 1 és 1200 közötti számra fel kell írni.
- A
<záró-pont> egy olyan pont jel, amit legalább egy nem látható
karakter (szóköz, újsor, tabulátor) követ.
- A
<kifejezés N> szabályában szereplő <köz> legalább egy nem
látható karaktert jelöl, de csak abban az esetben, ha az őt követő
kifejezés nyitó zárójellel kezdődik.
- A
{ <kifejezés> } szerkezet azonos a
{}(<kifejezés>) struktúrával
- Egy
<füzér> idézőjelek (") közé zárt karaktersorozat,
általában a karakterek kódjainak listájával azonos
- <név>-ként
a következő jelsorozatok megengedettek
- kisbetűvel
kezdődő alfanumerikus jelsorozat (ebben megengedve kis- és
nagybetűt, számjegyeket és aláhúzásjelet);
- egy
vagy több ún. speciális jelből (+-*/\^<>=`~:.?@#$&)
álló jelsorozat;
- az
önmagában álló ! vagy ;
jel;
- a
[] {} jelpárok;
- aposztrófok
(') közé zárt tetszőleges jelsorozat, amelyben \ jellel kezdődő
escape-szekvenciákat is elhelyezhetünk.
- Egy
<változó> nagybetűvel vagy aláhúzással kezdődő alfanumerikus
jelsorozat lehet.
- <természetes szám> lehet
- (decimális)
számjegysorozat;
- 2,
8 és 16 alapú számrendszerben felírt szám, ilyenkor a számjegyeket rendre
a 0b, 0o, 0x karakterekkel kell prefixálni;
- karakterkód-konstans
0'c alakban, ahol c egyetlen karakter, esetleg escape szekvencia
formájában megadva (az escape szekvenciák formája megegyezik a C nyelvben
találhatókéval).
- A
<lebegőpontos szám> mindenképpen tartalmaz tizedespontot, ennek
mindkét oldalán legalább egy számjeggyel. Az e vagy E betűvel jelzett
exponens nem kötelező.
- Az
egyes lexikai elemek között szabadon előfordulhatnak nem látható
karakterek és megjegyzések. Kivétel: a struktúrakifejezés neve és az azt
követő nyitó zárójel között nem lehet más jel.
- A
megjegyzések két alakja megengedett:
- A
% százalékjeltől a sor végéig
- A
/* jelpártól a legközelebbi */ jelpárig.
Alapból a nyelv ezeket nem tudja, de lehet valami
hasonlót elérni. Mivel a predikátumok illesztésekor gyakorlatilag tetszőleges
"típus" melynek természetesen van értelme, lehet a formális
paraméter, így a függvény template-hez valami nagyon közeli fogalom jön létre.
Ez természetesen összetett adatszerkezetekre is megvalósítható.
Beépített predikátumok formájában megtalálható az on_exception és a raise_exception vagy throw, melyekkel a hagyományos kivétel- és hibakezelést valósíthatjuk meg. Ezek a rendszer által hiba esetén automatikusan "hívott" predikátumok. A kivétel tetszőleges "típus" lehet.
példa:
catch(Goal, Cacther, Recovery) :-
on_exception(Catcher, Goal,Recovery).
throw(Ball) :-
raise_exception(Ball).
Alapvetően kétféle hibakezelés van a Prolog rendszerekben:
·
Kapd el és dobd
(Catch and throw)
Hiba esetén a rendszer visszalép (felgöngyölíti a
vermeit) ameddig egy megfelelő hibakezelő eljáráshívásig nem ér, majd
ott folytatja
·
Helyi hibakezelés
Hiba esetén a hibát okozó eljáráshívás helyébe lép a
hibakezelő eljárás meghívása. Megszakító jellegű hiba esetén a
hibakezelő beszúródik az hívásfolyamba. Erre
példa az unknown Prolog jelző, amivel előírhatjuk, hogy a nem
definiált eljárás hívása esetén mit csináljon a
rendszer.
throw/1, raise_exception/1
Hívási minta:
throw (@HibaKif)
raise_exception (@HibaKif)
Jelentés:
Se nem igaz, se nem hamis
Hatás:
Kiváltja a HibaKif hibahelyzetet
Kompatibilitás:
A két eljárás szinonima, de
raise_exception/1 SICStus Prolog specifikus.
catch/3, on_exception/3
Hívási minta:
catch ( :+Cél, ?Minta, :+Hibaág )
on_exception ( ?Minta, :+Cél, :+Hibaág )
Argumentumok:
Cél - Az argumentum egy meghívható kifejezés
Minta - Az argumentum egy tetszőleges kifejezés
Hibaág - Az argumentum egy meghívható kifejezés
Jelentés:
Igaz, ha call(Cél) igaz, vagy ha a hívását megszakította
throw/1 (vagy raise_exception/1) hívása egy olyan argumentummal, ami egyesíthető
Minta-val és call(Hibaág) igaz.
Hatás:
Ha Cél végrehajtása során hibahelyzet nem
fordul elő, futása azonos Cél-lal. Ha Cél-ban hiba van, a hibát leíró kifejezést egyesíti Minta-val. Ha ez sikeres, meghívja
a Hibaág-at. Ellenkező esetben tovább göngyölíti a Prolog eljárásvermét
további körülvevő catch/1 (on_exception/1) hívásokat keresve, és ezekre
megismétli az eljárást.
A
SICStus Prolog minden eljárást valamilyen modulban helyez el. Amig nem
intézkedünk másképp, az eljárások alaphelyzetben a user
modulba kerülnek.
Ha Prolog programunkat strukturálni kívánjuk, akkor ún. modul-állományokat
kell létrehoznunk. Egy állományban egy modult tudunk elhelyezni, az állomány
első programeleme egy modul-parancs kell legyen:
:-
module(Modulnév,[Funktor1,Funktor2,...]).
Itt Funktor1, ... a modulból
exportálni kivánt eljárások funktorai (azaz Név/Aritás alakú kifejezések, ahol
Név egy atom, Aritás egy egész).
Például, ha egy korábban definiált fennsik/3 eljárást egy modulba kivánjuk
foglalni, akkor a szükséges eljárásokat be kell írnunk egy állományba, mondjuk
plato.pl -be, és ennek az állománynak az elejére el
kell helyeznünk a következő parancsot:
:-
module(plato_kereses,[fennsik/3]).
Ha ezután be akarjuk tölteni ezt a modult, akkor a SICStus rendszer
promptjánál ki kell adnunk egy use_module parancsot, argumentumában az
állománynévvel:
:- use_module(plato).
Ez a parancs az adott állományban levő modult betölti, és az általa
exportált összes eljárást importálja a kurrens modulba (példánkban a user modulba). Ezáltal az importált eljárások ebből a
modulból hivhatókká válnak. Ugyanezt a beépitett eljárást használhatjuk a
SICStus könyvtárak betöltésére is, pl. a lists könyvtárat a következőképpen
tölthetjük be:
:- use_module(library(lists)).
A use_module beépitett eljárásnak van egy kétargumentumú változata, ez betölti
a modult, de csak azokat az eljárásokat importálja, amelyek funktorai
szerepelnek a második argumentumbeli import-listában. Pl:
:-
use_module(library(lists),[last/2]).
csak a last/2 eljárást fogja láthatóvá tenni, a többi könyvtári eljárást nem.
Ekkor például lehet egy saját append eljárásunk, anélkül, hogy ez a könyvtári
példánnyal összeütközésbe kerülne.
A use_module parancs szerepelhet egy állományban, akár egy modul-állományban
is. Ez utóbbi esetben csak ebbe a modulba fogja importálni a betöltött
eljárásokat. Ugyanazt a modul-állományt több modulba is betölthetjük, ez nem
jár felesleges memóriafoglalással, mivel a SICStus Prolog rendszer az
eljárásokat csak egy példányban tárolja.
A SICStus Prolog rendszer modulfogalma nem szigorú. Bármely betöltött eljárás meghívható,
ha az ún. modul-kvalifikált hívási formát használjuk,
azaz az eljáráshívás elé írjuk a modulnevet, attól a kettőspont
operátorral elválasztva. Ha például a fennsík kereső
programot a fent példaként idézett módon foglaltuk modulba, és azt betöltjük,
akkor a fennsik/3 eljárást modul kvalifikálás nélkül tudjuk hívni, de a többi
eljárást is meghívhatjuk, például:
| ?-
plató_keresés:első_fennsik([1,2,2,3],4,F,H,L).
A SICStus rendszernek ez a tulajdonsága különösen hasznos modularizált
programok nyomkövetésénél.
Végezetül következzék néhány, a magasabbrendű eljárások használata során
felmerülő, a modularitással kapcsolatos fontos tudnivaló. A magasabbrendű
(meta-) eljárás egy olyan eljárás, amelynek egy másik eljárás az argumentuma.
Világos, hogy ha modulközi meta-eljárásokat írunk, azaz a meta-eljárás által meghívandó
eljárás más modulban van, akkor szükség van arra, hogy az eljárás
meta-argumentumát modul-kvalifikált módon adjuk át. Ezért a meta-eljárásokra
egy meta_predicate deklarációt kell megadnunk, amelyben jelezzük, hogy melyek
az eljárás-argumentumok.
A meta-deklaráció formája:
:- meta_predicate
<eljárásnév>(<argleiró1>,...)
Itt az argleiró lehet a : jel, annak jelzésére, hogy az adott argumentum egy
eljárás, vagy bármilyen más atom a többi argumentum jelzésére. Ez utóbbi
helyeken szokás a be- ill. kimenő jellegre utaló jeleket elhelyezni (+,-,?).
Alapvetően kétféle modulfogalom lehetséges:
·
név-alapú
·
eljárás-alapú
1.
Név-alapú modell
Egy név minden előfordulása (eljárás, konstans,
struktúra) vagy látható (visible) vagy lokális (local) az adott modulban.
A lokális nevek csak az adott modulban láthatók, azaz más modulban nem nevezhetők
meg. Ez legegyszerűbben úgy képzelhető el, hogy egy r lokális
névnek egy m modulban való minden előfordulása átneveződik
pl. az 'm:r' névvé.
Előnyök:
·
egyszerű
modell
·
metahívások
automatikusan jól kezelődnek, pl.:
module m1.
export(p/1).
...
p(X) :- ..., X, ...
...
module m2.
import(p/1).
...
q :- p(r).
r :- ...
module m2.
import(p/1).
...
q :- p('m2:r').
'm2:r' :- ...
Hátrányok:
·
nem lehetséges pl. p/1 -et exportálni, de p/2 -t lokálissá
tenni.
·
az adatnevek
(struktúra/konstans) és a velük azonos alakú eljárásnevek láthatósága egymáshoz
van kötve
·
az adatnevek
alaphelyzetben általában lokálisak, láthatóságukat deklarálni kell.
2. Eljárás-alapú modell
A kívülről való láthatóságot eljárásokhoz és nem
nevekhez kötjük.
Az adatnevek általában mindig láthatóak.
Előnyök:
·
lehetséges pl. p/1-et exportálni, és p/2-t lokálissá tenni
·
az adatnevek
(struktúra/konstans) és a velük azonos alakú eljárásnevek láthatósága nincs
egymáshoz kötve
Hátrányok:
·
bonyolultabb
modell
·
metahívások
kezelése külön mechanizmust igényel :
modul-környezet nyilvántartás
Futás közben a rendszer állandóan nyilvántartja, mely
modulban vagyunk. Ez közönséges eljárások esetén az eljárás definícióját
tartalmazó modul. A meta-eljárásokat (pl. p/1 alább) azonban átlátszóaknak kell
deklarálni.
:- module_transparent p/1.
Az ilyen eljárások esetén a modul-környezet a hívótól öröklődik.
A modul-környezetet használjuk annak megállapitására, hogy egy meta-hívást mely
modulban értelmezzünk.
Például:
:- module (m1, p/1).
%az m1 modul exportálja a p/1 eljárást
:- module_transparent p/1
p(X) :- ..., X, ...
...
:- module m2.
q :- p(r), ...
r :- ...
A p eljárás meghívásakor m2 marad a modul-környezet, mert p/1 átlátszó, így X hívásakor
az X=r eljárást m2-ben keressük.
meta-argumentumok nyilvántartása
A meta-eljárásoknál meg kell nevezni a
meta-argumentumpoziciókat, pl. egy olyan p/3 esetén, melynek a 3. argumentuma
eljárás:
:- meta_predicate p(+,+,:).
A meta_predicate deklarációt minden olyan modulban szerepeltetni kell, ahol az
adott eljárást meghívjuk!
A fordítóprogram az adott argumentumpoziciót minden hívásban kiegészíti, pl:
:- module(m2).
:- meta_predicate p(:).
q :- p(r). --> q :-
p(m2:r).
Létezik objektum orientált kiterjesztése a Prolog nyelvnek, és sikerült teljesen a standard Prolog szintaktikán belül megvalósítani, így könyvtárkiterjesztésként "tetszőleges" Prolog környezetbe beilleszthető. A Prolog objektumok prototípusokon alapulnak. Az OOP elveiből az öröklődés és az üzenetküldés elve került megvalósításra.
A Prolog objektumai predikátum definíciók gyűjteménye.
Ilyen értelemben az Objektum nagyon közeli fogalom a Prolog Modulhoz. Valójában
az objektum nem is más, mint a Prolog modul rendszerének kibővítése. Az
objektumon belül találhatók:
- Attribútum
(ez módosítható)
- Metódus
(ez predikátum definíció)
Az objektumok akár fájlban is elhelyezkedhetnek, ezt a
modul rendszerhez hasonlóan kell a rendszernek akkor beolvasnia a közös logikai
univerzumba. Az alapértelmezett öröklődés a felülírás (override) módszer,
azaz amikor az újradefiniált metódusok/attribútumok eltakarják az ős
azonos jellemzőit. Az Objektum univerzumban van egy közös ős
objektum, az "object", melyből direkt, vagy indirekt módon
minden objektum kreálódik. Az objektumok miután könyvtárban lettek a nyelvhez
kiterjesztésként megvalósítva, ezért az alábbi módon "élesíthetők":
?- use_module(library(objects)).
Ekkor az alábbi operátorok újradefiniálódnak, az
alábbi precedenciával:
:- op(1299, xfy, [ & ]).
:- op(1198, xfx, [ :- ]).
:- op(1198, fx, [ :- ]).
:- op(550, xfx, [ ::, <: ]).
:- op(550, fx, [ ::, <: ]).
Az objektumok deklarációja az alábbi módon történik:
<objektumazonosító> :: {
<mondat1> &
<mondat2> &
.
.
<mondatn>
}.
Ahol az objektumazonosító egy Prolog term, a mondatok pedig metódus direktívák. Példa:
apt ::
{ super(apartment) &
street_name('York') &
street_no(100) &
wall_color(white) &
floor_surface(wood)
}.
Itt a super az ősosztályt jelöli. Ugyanez
attribútumokkal:
apt ::
{ super(apartment) &
attributes([ street_name('York'),
street_no(100),
wall_color(white),
floor_surface(wood)
])
}.
18.
A Prolog egy OO kiterjesztése: a Prolog++
16.1Bevezető gondolatok a PROLOG++ programozási nyelvről
16.3A
Prolog++ programozási nyelv története, szerzői, futtatási környezet
16.5Osztály
hierarchiák és öröklődés
16.6Objektumok
16.7Prolog++
és C++
16.1 Bevezető gondolatok a Prolog++
programozási nyelvről
A nyelvről szinte
minden forrásban (külföldi sajtó) dicsérő szavakat lehet olvasni amióta
megjelent. Kifejező és nagy erejű objektum orientált rendszerről
van szó, amely kombinálja az AI (Mesterséges Inteligencia) és OOP (Objektum
Orientált Programozás) hatóerejét. Az objektumok (vagy osztályok) a legmagasabb
szinten vannak definiálva. Lehetséges definiálni objektumok rendszerét Prolog++
-szal, manipulálni azokat Prolog szabályok segítségével, ez egy erős
eszköz ‘furfangos’ programozók számára. Párhuzamot fedezhetünk fel
a C és C++, valamint Prolog és Prolog++ nyelvek között. De amíg a C++ egy procedurális
nyelvet kombinál az OOPs-sel, addig a Prolog++ egy dekleratív nyelvet kombinál
az OOPs-sel.
16.2
Általános tapasztalatok
Annak ellenére, hogy az
interneten szinte mindenhol pozitív kritikákat lehet olvasni a
rendszerről, nem mondható, hogy igazán elterjedt volna. Még Prologosok
körében sem lett akkora átütő siker, mint például a C-ben dolgozók körében
annak idején a C++ megjelenése. Google, Altavizsla, valamint az Index
keresőjével próbáltam rábukkanni valamilyen magyar utalásra a programozási
nyelvről, de nem jártam sikerrel. Külföldi oldalakon persze már annál
inkább találhatunk anyagot, ha viszont nem csak olvasni szeretnénk a PROLOG++
-ról, hanem ki is szeretnénk próbálni a rendszert, akkor az már akadályba
ütközik. Nem sikerült fellelnem szabadon letölthető verziót, ami
használható lenne, csupán olyanokat, amelyekért komoly pénzeket kellene
fizetni. Annak ellenére van ez így, hogy főleg oktatási célokra ajánlják a
rendszert. Így sajnos csak a PROLOG++ Reference –re illetve egyéb
internetes újságokban megjelent cikkekre tudok támaszkodni nyelvi leírásom
során. A PROLOG++ Reference nem csupán a nyelvről szól, hanem
általánosságban is sokat foglalkozik az ‘Objektum Orientált
Világgal’.
16.3
A Prolog++ programozási nyelv története,
szerzői, futtatási környezet
A Prolog++ nyelv egy
érett, jól átgondolt termék, amelyet a Logic Programming Associates (LPA)
fejlesztett ki 640K MS-DOS számítógépekre 1989-ben. Emiattt hatékony és kompakt
run-time rendszer. Azóta az LPA továbbfejlesztette a rendszert Windows és
Machintosh gépekre is az igényeknek megfelelően. Így ma már kapható MacOS,
MS-DOS, MS-Windows, Windows 95, Windows NT rendszerekkel kompatibilis 2.0 verzió is, persze igen borsos áron. Ezt a rendszert a
Studio 4 dobta piacra, amely egy londoni székhelyű vállalat. A Prolog történetének
áttekintése:
1972 – Marseille
(PROgramming in LOGic)
1975 – NIM IGU:SZI
1978 – PROLOG
fordító
1982 – MPROLOG,
TPROLOG
1985 – TC PROLOG
198x – Turbo
PROLOG
1984 –
mikroPROLOG
1989 – PROLOG++
199x – PROLOG++
2.0 (MacOS, Windows NT, ...)
A következő ábra
segít abban, hogy el tudjuk helyezni a nyelvek között a PROLOG++ terméket.
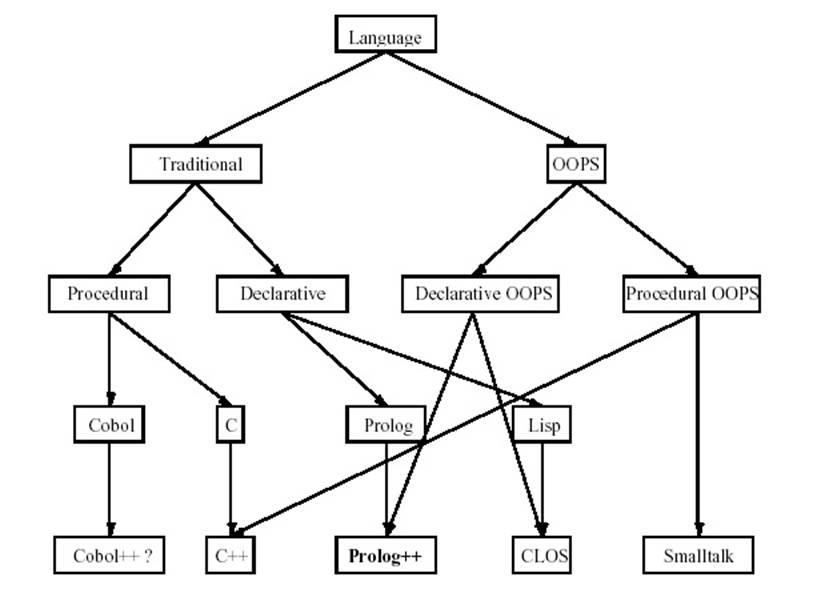
16.4 Nyelvi
elemek, szintaxis
Gyakorlatilag semmi
újdonságot nem lehet elmondani az általános Prologhoz képest. Termekről,
egyszerű állításoktól, lekérdezésekről valamint levezetési
szabályokról beszélhetünk, melyeknek a szintaxisa definiált. A különböző
nyelvi elemek teljesen hasonlóan használhatók, mint Prologban.
A Prolog elemei:
Tények: (pl. szuloje(a,b).)
Szabályok: (pl. nagyszuloje(X,Y) ha szuloje(X,Z) és szuloje(Z,Y))
Kérdések (pl. szuloje(a,X)?) - mintaillesztés mindenféle lehetséges
kérdésre
Írásmód:
kulcsszavas – ha (if) és
(and) vagy (or)
írásjeles – :- , ;
16.5
Osztály hierarchiák és öröklődés
Osztály hierarchiák
vannak implementálva jelentésük szerint egy osztályon belül, minden osztályban
szerepel a szülő osztály. A metódusok és
attribútumok öröklődése ennek segítségével kerül megvalósításra. Így
elmondható, hogy a Prolog++ a többszörös öröklődést segíti a szülői
függőség segítségével. Minden osztály tulajdonképpen egy template, amely
definiálja az általános karakterisztikáját a példánynak. Nézzünk egy
egyszerű példát, amelyből látszik, hogy szintaktikailag hogy lehet
osztályokat létrehozni, illetve az öröklődést megvalósítani:
class bicycle.
parts frame, wheel *
2, seat, handle_bars.
end bicycle.
class unicycle.
inherit bicycle.
parts wheel,
handle_bars * 0.
end unicycle.
class tandem.
inherit bicycle.
parts seat * 2,
handle_bars * 2.
end tandem.
...
class
cycle_component.
public method
when_created/0.
when_created :-
write(
'Created:
' ),
write(
self ), nl.
end cycle_component.
A következő kulcsszavak nagyon fontosak:
- composite_part:
összetett rész, a legfontosabb példány a hierarchia ezen részében
- super_part:
a szuper vagy szülő példány, egyes irodalomban ősosztályként is
említik
- sub_part:
egy helyettesítő vagy gyerek része ennek a példánynak
- #: egy
speciálisan számozott helyettesítő rész
Az objektumon belül
található két ‘dolog’: attribútum és metódus. Fontos még
megemlíteni, hogy az objektumok akár fájlban is elhelyezkedhetnek. Elmondható,
hogy alapértelmezett öröklődés értelem szerűen
a felülírás.
Ahol az objektumok
találhatók, azt általában az irodalom objektumok univerzumának szokta nevezni.
Ebben az univerzumban van egy közös ős, amelynek a neve
‘object’. Ebből a közös ősből fog minden objektum
létrejönni direkt vagy indirekt.
18.6 Objektumok
Prolog++ támogatja
egyaránt a statikus és a dinamikus objektumokat is. A dinamikus objektumok
kreálhatók vagy argumentumok adhatók számukra futásidőben, míg a statikus
objektumok fixnek mondhatók és fordítási időben optimalizálódnak.
18.7 Prolog++ és C++
A C++ nyelv,
akárcsak a PROLOG++, egy objektum-orientált kiterjesztése az elődjének. A
C++ erősen típusos nyelv, míg a Prolog++ -ról ugyanez nem mondható el. A
Prolog++ támogatja a gyors fejlesztést és a prototípus
készítést.
A Prolog++ -nak
megvan az az előnye, hogy late-binding tulajdonsággal bír, amelynek
előnyeit programfejlesztés során élvezhetjük ki. Ez abból adódik, hogy a
Prolog egy run-time system. Minden üzenet csak a függvény hívásakor váltódik
ki. A C++ -ban két fajtája van a metódusoknak: normál függvény és in-line
függvény. Alapértelmezésben a metódusok válaszüzenetei a compiler által
definiáltak.
Operator overloading
(operátor túlterhelés) a C++ esetében nagyon fontos nyelvi fogásnak
tekinthető. Prolog++-ban egy operátor pusztán szintaktikus elem, egy
függvénye a relációnak.
Miután logikai tételbizonyításokkal procedurálisan (de
nem logikailag!) ekvivalens programok végrehajtása a Prolog nyelv tárgya, így a
nyelvi helyességbizonyítás szükségtelen - mivel a feladat megfogalmazása
logikai axiómák és tételek formájában, majd annak transzformációja standard
Prolog notációra a helyességbizonyításon alapul.
A logikai programok a párhuzamosság kihasználására
számos lehetőséget kínálnak, ezek közül a legismertebbek a
VAGY-párhuzamosság ill. az ÉS-párhuzamosság. Mind a kettőnek meg van a
maga előnye és hátránya is, a Prolog implementációk azonban a
VAGY-párhuzamosságot valósítják meg a nyelv sajátosságai miatt. A Prolog
rendszer párhuzamossága implicit! Azaz a programozónak semmit sem kell tennie
programja párhuzamos futtatásához, pusztán a fenti paradigmának megfelelően
megfogalmazni azt, hogy a párhuzamos végrehajtásnak legyen értelme. A Prolog
jelenlegi implementációi a Muse rendszert használják
mint a párhuzamosság "motorját".
A Prolog könyvtárhierarchiája nagyon terebélyes, és gyakorlatilag minden lényeges funkció megvalósított, az I/O műveletektől az ablakozó-rendszerig. A szabványosság kérdése ugyanakkor nem megoldott, ahány implementáció annyiféle könyvtár-hierarchia.
Programbetöltés
Adott forrásfájl vagy tárgykód betöltését jelenti a
Prolog fejlesztői környezetbe. Szabványos predikátuma az ensure_loaded/1, paramétere egy fájlnév, vagy fájlnevek listája.
Minden fájlra nézve ellenőrzi annak korát, és csak akkor tölti be, ha
szükséges.
I/O
műveletek:
A szövegfájlokat háromféle módban lehet megnyitni,
ezek: read,
write, append. Megnyitás az open/3 művelettel történik, argumentumai sorra: fájl
neve, megnyitás módja és a csatorna neve.
Például, ha az F fájlból akarunk olvasni:
open(F, read, R)
Ezután műveleteink az R csatornára vonatkoznak,
egészen a csatorna lezárásáig. Ezt a close/1 művelettel tehetjük meg. A
szabványos bemeneti és kimeneti csatornákra user néven hivatkozhatunk, ezeket
nem kell (és nem is lehet) megnyitni és lezárni.
Az I/O utasítások lehetnek karakter, vagy term
szintűek.
Karakter szintű utasítások:
·
peek_code(F,C) ez akkor igaz, ha az F csatorna aktuális karakterének
kódja egyezik C-vel.
·
get_code(F,C) hasonló, mint a peek_code(F,C), csak hatására az F
csatorna aktuális karaktere a következő lesz.
·
at_end_of_stream(F) igaz, ha az F csatornát már végigolvastuk.
·
put_code(F,C) az F csatornára kiírja a C kódú karaktert
·
nl(F) sort emel
Term szintű utasítások:
·
read(F,T) egy termet olvas be
az F csatornáról és megpróbálja T-vel illeszteni. A beolvasandó termet mindig
egy pont és egy elválasztó karakter zárja le.
·
write(F,T) kiír egy termet az
F csatornára, lezáró pont nélkül, tehát általában nem visszaolvasható kimenetet
kapunk (hisz az feltételezi a pont és elválasztó karakter jelenlétét).
·
writeq(F,T) ezt akkor
használjuk, ha visszaolvasható kimenetet szeretnénk, a T termet lezáró ponttal
együtt írja ki.
Például ha egy fájl végéhez hozzá akarunk fűzni
egy másik fájlt, az elsőt append módban, a másodikat read módban nyissuk
meg. Érdemes karakterenként beolvasni, és kiírni, ha nem tudjuk, hogy a bemenet
termenként olvasható-e. A „-1”-es karakterkód jelenti a fájl végét,
ekkor zárjuk le a csatornákat.
%appf(F1,F2)
:- az F1 fájl végére beszúrja F2.t
appf(F1,F2) :-
open(F1,append,A), open(F2,read,R), af(A,R)
af(A,R) :- get_code(R,C),
( C == -1 -> close(A), close(R)
; put_code(A,C), af(A,R)
).
- egy Prolog-implementáció Linuxra
- egy egyszerű, szabadon letölthető
Windows-os Prolog-interpreter
- ha többet szeretnél tudni a Prologról
Egyéb linkek:
A prolog nyelvről:
http://www.cs.cmu.edu/afs/cs.cmu.edu/project/ai-repository/ai/lang/prolog/0.html
http://src.doc.ic.ac.uk/bySubject/Computing/Languages.html
http://fas.sfu.ca/0/cs/people/ResearchStaff/jamie/personal/prolog-faq.1
http://www.sics.se/isl/sicstus2.html
Dr.
Ásványi Tibor honlapja
A
logikai programozásról és a mesterséges intelligenciáról:
PROLOG++szal kapcsolatos linkek:
Érdemes
még a következő linkekre is ellátogatni:
http://www.lpa.co.uk/dow_doc.htm
http://www.sxst.it/lpa__ppp.htm
http://www.hallogram.com/science/prolog/
http://www-lp.doc.ic.ac.uk/UserPages/staff/ft/alp/news/books/ppp.html
a prolog++ nyelvleírást készítette: Tóth Gábor,
tg@inf.elte.hu (utolsó módosítás: 2003-07-08) kiegészítette: Joósz
Mária (utolsó módosítás: 2005-07-07) kiegészitette:
Vén Attila
(utolsó módositás: 2006. február 1.)